如果你使用 Spark RDD 或者 DataFrame 编写程序,我们可以通过 coalesce 或 repartition 来修改程序的并行度:[code lang="scala"]val data = sc.newAPIHadoopFile(xxx).coalesce(2).map(xxxx)或val data = sc.newAPIHadoopFile(xxx).repartition(2).map(xxxx)val df = spark.read.json("/user/iteblog/json").repartition(4).map(xxxx)val df = spark.read.json("/user/iteblog/json").coalesce(4).map(x w397090770 6年前 (2019-01-24) 8154℃ 0评论12喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 9年前 (2015-11-06) 7963℃ 0评论9喜欢
在《Kafka集群扩展以及重新分布分区》文章中我们介绍了如何重新分布分区,在那里面我们基本上把所有的分区全部移动了,其实我们完全没必要移动所有的分区,而移动其中部分的分区。比如我们想把Broker 1与Broker 7上面的分区数据互换,如下图所示:可以看出,只有Broker 1与Broker 7上面的分区做了移动。来看看移动分区之 w397090770 9年前 (2016-03-31) 3338℃ 0评论4喜欢
快速管理和访问 PB 级数据的能力对于整个数据生态系统的可伸缩增长是至关重要的。尽管如此,这种对规模和速度的综合需求并不总是自然地适合现有的批处理和流系统架构。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHudi 于 2016 年以“Hoodie”为代号开发,旨在解决 Uber 大数据生态系统 w397090770 6年前 (2019-04-20) 933℃ 0评论1喜欢
近日,Intel开源了基于Apache Spark的分布式深度学习框架BigDL。有了BigDL之后,用户可以像编写标准的Spark程序一样来编写深度学习(deep learning)应用程序,编写完的程序还可以直接运行在现有的Spark或者Hadoop集群之上。BigDL主要有以下三大特点:[gt href="https://github.com/intel-analytics/BigDL " rel="nofollow"]BigDL GitHub地址[/gt]丰富的深度学习算法支 w397090770 8年前 (2017-01-19) 4428℃ 0评论14喜欢
在《Hadoop 1.x中fsimage和edits合并实现》文章中提到,Hadoop的NameNode在重启的时候,将会进入到安全模式。而在安全模式,HDFS只支持访问元数据的操作才会返回成功,其他的操作诸如创建、删除文件等操作都会导致失败。 NameNode在重启的时候,DataNode需要向NameNode发送块的信息,NameNode只有获取到整个文件系统中有99.9%(可以配 w397090770 11年前 (2014-03-13) 17328℃ 3评论16喜欢
1、内存不够[code lang="JAVA"][ERROR] PermGen space -> [Help 1][ERROR] [ERROR] To see the full stack trace of the errors,re-run Maven with the -e switch.[ERROR] Re-run Maven using the -X switch to enable full debug logging.[ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles:[ERROR] [Help 1]http://cwiki.apache.org/confluence/display/MAVEN/OutOfMemoryErr w397090770 11年前 (2014-04-16) 15499℃ 4评论9喜欢
虽然Web网页也提供了垮因特网和组织界限访问应用的方式,但Web服务与Web网页并不一样。Web网页直接面向的是人,而Web服务的开发目标是访问者既可以是人也可以是自动化的应用程序。因此,分析一下“软件即为服务”的理念是非常有价值的,这个理念也是Web服务技术的基础。 “软件即为服务”这一理念非常新颖,它首先 w397090770 12年前 (2013-05-07) 3210℃ 0评论2喜欢
1.hbase怎么预分区?2.hbase怎么给web前台提供接口来访问?3.htable API有没有线程安全问题,在程序中是单例还是多例?4.hbase有没有并发问题?5.metaq消息队列,zookeeper集群,storm集群,就可以完成对商城推荐系统功能吗?还有没有其他的中间件?6.storm 怎么完成对单词的计数?7.hdfs的client端,复制到第三个副本时宕机, w397090770 8年前 (2016-08-26) 4144℃ 0评论2喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 21959℃ 5评论40喜欢
流式处理是大数据应用中的非常重要的一环,在Spark中Spark Streaming利用Spark的高效框架提供了基于micro-batch的流式处理框架,并在RDD之上抽象了流式操作API DStream供用户使用。 随着流式处理需求的复杂化,用户希望在流式数据中引入较为复杂的查询和分析,传统的DStream API想要实现相应的功能就变得较为复杂,同时随着Spark w397090770 8年前 (2016-11-16) 6097℃ 0评论13喜欢
近日,红杏官方为了方便开发人员,公布了红杏公益版代理,该代理地址和端口为hx.gy:1080,可以在浏览器、IDE里面进行设置,并且访问很多常用的网站。目前支持的域名如下:[code lang="scala"]android.combitbucket.orgbintray.comchromium.orgclojars.orgregistry.cordova.iodartlang.orgdownload.eclipse.orggithub.comgithubusercontent.comgolang.orggoogl w397090770 10年前 (2015-04-15) 18250℃ 0评论22喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi w397090770 3年前 (2021-11-16) 463℃ 0评论1喜欢
面试题目:输入n个整数,输出其中最小的前k个数。 例如输入1,2,3,4,5,6,7和8这8个数字,则最小的3个数字为1,2,3。 分析:这道题最简单的思路莫过于把输入的n个整数排好序,然后输出前面k个数,这就是最小的前k个数。但是按照这种思路最好的时间复杂度为O(nlogn),是否还有比这个更快的算法呢? w397090770 12年前 (2013-05-21) 5637℃ 0评论2喜欢
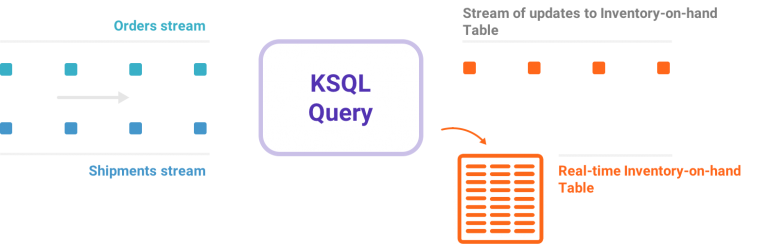
我非常高兴地宣布KSQL,这是面向Apache Kafka的一种数据流SQL引擎。KSQL降低了数据流处理这个领域的准入门槛,为使用Kafka处理数据提供了一种简单的、完全交互的SQL界面。你不再需要用Java或Python之类的编程语言编写代码了!KSQL具有这些特点:开源(采用Apache 2.0许可证)、分布式、可扩展、可靠、实时。它支持众多功能强大的数据流 w397090770 7年前 (2017-08-30) 7900℃ 0评论22喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》本博客收集到的Hadoop学习书籍分享地 w397090770 11年前 (2014-02-14) 202547℃ 5评论421喜欢
导语:此套面试题来自于各大厂的真实面试题及常问的知识点。如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待。如果公司急招人,你回答出来面试官70%,甚至50%的问题他都会要你,如果这个公司不是真正缺人,或者只是作人才储备,那么你回答很好,他也可能不要你,只是因为没有眼缘;所以面 zz~~ 3年前 (2021-09-24) 2303℃ 0评论9喜欢
我们可以在初始化 SparkSession 的时候进行一些设置:[code lang="scala"]import org.apache.spark.sql.SparkSessionval spark: SparkSession = SparkSession.builder .master("local[*]") .appName("My Spark Application") .config("spark.sql.warehouse.dir", "c:/Temp") (1) .getOrCreateSets spark.sql.warehouse.dir for the Spark SQL session[/code]也可以使用 SQL SET w397090770 4年前 (2020-09-09) 3296℃ 0评论2喜欢
如果你想搭建伪分布式Hadoop平台,请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》 经过好多天的各种折腾,终于在几台电脑里面配置好了Hadoop2.2.0分布式系统,现在总结一下如何配置。 前提条件: (1)、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令 w397090770 11年前 (2013-11-06) 21278℃ 6评论27喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 9年前 (2016-04-06) 13883℃ 0评论8喜欢
在使用 Apache Spark 的时候,作业会以分布式的方式在不同的节点上运行;特别是当集群的规模很大时,集群的节点出现各种问题是很常见的,比如某个磁盘出现问题等。我们都知道 Apache Spark 是一个高性能、容错的分布式计算框架,一旦它知道某个计算所在的机器出现问题(比如磁盘故障),它会依据之前生成的 lineage 重新调度这个 w397090770 7年前 (2017-11-13) 10484℃ 0评论24喜欢
FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:下载(Download)和上传(Up w397090770 6年前 (2018-05-23) 5212℃ 0评论7喜欢
为期三天的 Spark+AI Summit Europe 于 2018-10-02 ~ 04 在伦敦举行,一如往前,本次会议包含大量 AI 相关的议题,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark+AI Summit Europe 2018 吸引了全球大量技术大咖参会,本次会议议题超过了140多个。会议的全部日程请参见:https://databricks.com/sparkaisummit/europe/schedule。注意 w397090770 6年前 (2018-10-13) 3476℃ 1评论8喜欢
引言:十年沉淀、全球宽表排名第一、阿里云首发云Cassandra服务ApsaraDB for Cassandra是基于开源Apache Cassandra,融合阿里云数据库DBaaS能力的分布式NoSQL数据库。Cassandra已有10年+的沉淀,基于Amazon DynamoDB的分布式设计和 Google Bigtable 的数据模型。具备诸多优异特性:采用分布式架构、无中心、支持多活、弹性可扩展、高可用、容错、一 w397090770 5年前 (2019-09-05) 2153℃ 0评论4喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2015-04-25) 37445℃ 8评论55喜欢
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3459℃ 0评论3喜欢
本书于2015年04月出版,共168页,这里提供的是本书的完整版. w397090770 9年前 (2015-08-24) 3178℃ 0评论5喜欢
Apache HBase 1.2.1 于2016-04-12正式发布了,HBase 1.2.1是HBase 1.2.z版本线上的第一个维护版本,该版本的主题仍然是为Hadoop和NoSQL社区带来稳定和可靠的数据库。此版本在1.2.0版本上解决了27个issues。主要的Bug修改* [HBASE-15441] - Fix WAL splitting when region has moved multiple times* [HBASE-15219] - Canary tool does not return non-zero exit code when w397090770 9年前 (2016-04-14) 3125℃ 0评论2喜欢
上海Spark meetup第七次聚会将于2016年1月23日(周六)在上海市长宁区金钟路968号凌空SOHO 8号楼 进行。此次聚会由Intel联合携程举办。大会主题 1、开场/Opening Keynote: 张翼,携程大数据平台的负责人 个人介绍:本科和研究生都是浙江大学;2015年加入携程,推动携程大数据平台的演进;对大数据底层框架Hadoop,HIVE,Spark w397090770 9年前 (2016-01-28) 2556℃ 0评论6喜欢
关于 Apache Spark 2.2.0 的详细新功能介绍请参见:《Apache Spark 2.2.0新特性详细介绍》Apache Spark 2.2.0 持续了半年的开发,从RC1 到 RC6 终于在今天正式发布了。本版本是 2.x 版本线的第三个版本。在这个版本 Structured Streaming 的实验性标记(experimental tag)已经被移除,这也意味着后面的 2.2.x 之后就可以放心在线上使用了。除此之外,这 w397090770 7年前 (2017-07-12) 2814℃ 0评论8喜欢










![Spark+AI Summit Europe 2018 PPT下载[共95个]](https://www.iteblog.com/pic/spark/Spark_ai_summit_europe_2018-iteblog.png)